Note
Click here to download the full example code
Fit using the Model interface¶
This notebook shows a simple example of using the lmfit.Model class. For
more information please refer to:
https://lmfit.github.io/lmfit-py/model.html#the-model-class.
import numpy as np
from pandas import Series
from lmfit import Model, Parameter, report_fit
The Model class is a flexible, concise curve fitter. I will illustrate
fitting example data to an exponential decay.
def decay(t, N, tau):
return N*np.exp(-t/tau)
The parameters are in no particular order. We’ll need some example data. I
will use N=7 and tau=3, and add a little noise.
t = np.linspace(0, 5, num=1000)
data = decay(t, 7, 3) + np.random.randn(*t.shape)
Simplest Usage
model = Model(decay, independent_vars=['t'])
result = model.fit(data, t=t, N=10, tau=1)
The Model infers the parameter names by inspecting the arguments of the
function, decay. Then I passed the independent variable, t, and
initial guesses for each parameter. A residual function is automatically
defined, and a least-squared regression is performed.
We can immediately see the best-fit values:
print(result.values)
Out:
{'N': 6.984064047700289, 'tau': 3.0113542953210715}
and use these best-fit parameters for plotting with the plot function:
result.plot()
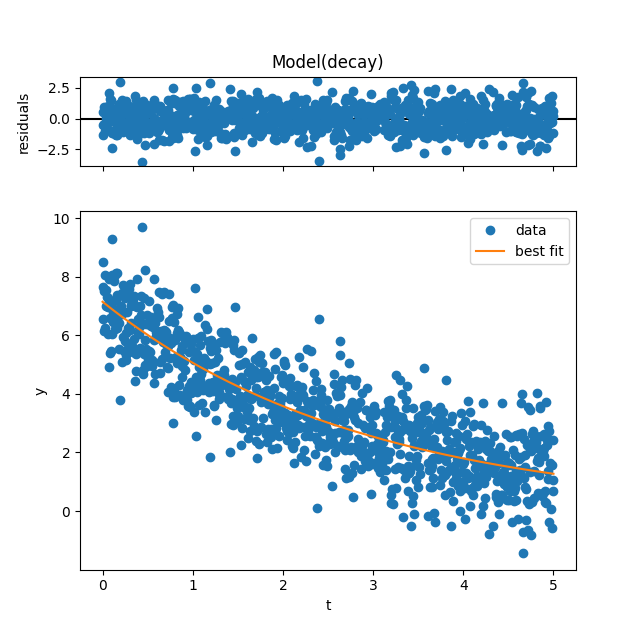
Out:
(<Figure size 640x640 with 2 Axes>, GridSpec(2, 1, height_ratios=[1, 4]))
We can review the best-fit Parameters by accessing result.params:
result.params.pretty_print()
Out:
Name Value Min Max Stderr Vary Expr Brute_Step
N 6.984 -inf inf 0.08845 True None None
tau 3.011 -inf inf 0.066 True None None
More information about the fit is stored in the result, which is an
lmfit.MimimizerResult object (see:
https://lmfit.github.io/lmfit-py/fitting.html#lmfit.minimizer.MinimizerResult)
Specifying Bounds and Holding Parameters Constant
Above, the Model class implicitly builds Parameter objects from
keyword arguments of fit that match the argments of decay. You can
build the Parameter objects explicity; the following is equivalent.
result = model.fit(data, t=t,
N=Parameter('N', value=10),
tau=Parameter('tau', value=1))
report_fit(result.params)
Out:
[[Variables]]
N: 6.98406405 +/- 0.08844670 (1.27%) (init = 10)
tau: 3.01135430 +/- 0.06600023 (2.19%) (init = 1)
[[Correlations]] (unreported correlations are < 0.100)
C(N, tau) = -0.756
By building Parameter objects explicitly, you can specify bounds
(min, max) and set parameters constant (vary=False).
result = model.fit(data, t=t,
N=Parameter('N', value=7, vary=False),
tau=Parameter('tau', value=1, min=0))
report_fit(result.params)
Out:
[[Variables]]
N: 7 (fixed)
tau: 3.00247383 +/- 0.04292226 (1.43%) (init = 1)
Defining Parameters in Advance
Passing parameters to fit can become unwieldly. As an alternative, you
can extract the parameters from model like so, set them individually,
and pass them to fit.
params = model.make_params()
params['N'].value = 10
params['tau'].value = 1
params['tau'].min = 0
result = model.fit(data, params, t=t)
report_fit(result.params)
Out:
[[Variables]]
N: 6.98406394 +/- 0.08844674 (1.27%) (init = 10)
tau: 3.01135441 +/- 0.06599962 (2.19%) (init = 1)
[[Correlations]] (unreported correlations are < 0.100)
C(N, tau) = -0.756
Keyword arguments override params, resetting value and all other
properties (min, max, vary).
result = model.fit(data, params, t=t, tau=1)
report_fit(result.params)
Out:
[[Variables]]
N: 6.98406394 +/- 0.08844674 (1.27%) (init = 10)
tau: 3.01135441 +/- 0.06599962 (2.19%) (init = 1)
[[Correlations]] (unreported correlations are < 0.100)
C(N, tau) = -0.756
The input parameters are not modified by fit. They can be reused,
retaining the same initial value. If you want to use the result of one fit
as the initial guess for the next, simply pass params=result.params.
#TODO/FIXME: not sure if there ever way a “helpful exception”, but currently
#it raises a ValueError: The input contains nan values.
#*A Helpful Exception*
#All this implicit magic makes it very easy for the user to neglect to set a
#parameter. The fit function checks for this and raises a helpful exception.
# #result = model.fit(data, t=t, tau=1) # N unspecified
#An extra parameter that cannot be matched to the model function will
#throw a UserWarning, but it will not raise, leaving open the possibility
#of unforeseen extensions calling for some parameters.
Weighted Fits
Use the sigma argument to perform a weighted fit. If you prefer to think
of the fit in term of weights, sigma=1/weights.
Out:
[[Variables]]
N: 7.33054986 +/- 0.26968212 (3.68%) (init = 10)
tau: 2.84538079 +/- 0.09473421 (3.33%) (init = 1)
[[Correlations]] (unreported correlations are < 0.100)
C(N, tau) = -0.929
Handling Missing Data
By default, attemping to fit data that includes a NaN, which
conventionally indicates a “missing” observation, raises a lengthy exception.
You can choose to omit (i.e., skip over) missing values instead.
data_with_holes = data.copy()
data_with_holes[[5, 500, 700]] = np.nan # Replace arbitrary values with NaN.
model = Model(decay, independent_vars=['t'], nan_policy='omit')
result = model.fit(data_with_holes, params, t=t)
report_fit(result.params)
Out:
[[Variables]]
N: 6.99349787 +/- 0.08886695 (1.27%) (init = 10)
tau: 3.00311360 +/- 0.06590577 (2.19%) (init = 1)
[[Correlations]] (unreported correlations are < 0.100)
C(N, tau) = -0.757
If you don’t want to ignore missing values, you can set the model to raise proactively, checking for missing values before attempting the fit.
Uncomment to see the error #model = Model(decay, independent_vars=[‘t’], nan_policy=’raise’) #result = model.fit(data_with_holes, params, t=t)
The default setting is nan_policy='raise', which does check for NaNs and
raises an exception when present.
Null-chekcing relies on pandas.isnull if it is available. If pandas
cannot be imported, it silently falls back on numpy.isnan.
Data Alignment
Imagine a collection of time series data with different lengths. It would be
convenient to define one sufficiently long array t and use it for each
time series, regardless of length. pandas
(https://pandas.pydata.org/pandas-docs/stable/) provides tools for aligning
indexed data. And, unlike most wrappers to scipy.leastsq, Model can
handle pandas objects out of the box, using its data alignment features.
Here I take just a slice of the data and fit it to the full t. It is
automatically aligned to the correct section of t using Series’ index.
model = Model(decay, independent_vars=['t'])
truncated_data = Series(data)[200:800] # data points 200-800
t = Series(t) # all 1000 points
result = model.fit(truncated_data, params, t=t)
report_fit(result.params)
Out:
[[Variables]]
N: 7.44820825 +/- 0.24899892 (3.34%) (init = 10)
tau: 2.80229162 +/- 0.12228516 (4.36%) (init = 1)
[[Correlations]] (unreported correlations are < 0.100)
C(N, tau) = -0.932
Data with missing entries and an unequal length still aligns properly.
model = Model(decay, independent_vars=['t'], nan_policy='omit')
truncated_data_with_holes = Series(data_with_holes)[200:800]
result = model.fit(truncated_data_with_holes, params, t=t)
report_fit(result.params)
Out:
[[Variables]]
N: 7.46253421 +/- 0.24975620 (3.35%) (init = 10)
tau: 2.79210670 +/- 0.12172740 (4.36%) (init = 1)
[[Correlations]] (unreported correlations are < 0.100)
C(N, tau) = -0.932
Total running time of the script: ( 0 minutes 0.251 seconds)