
Hi Everyone, I am facing a lot of problems when I am trying to fit my sample's spectra with my standards one. Initially, I used Athena to do the background subtraction, but the fitting results are just too "funny". The fitting does not really fit the actual spectra. Since I am analyzing Sulphur and many papers has reported how it is prone to self-absorption effect, I thought, probably if I am using a better background subtraction such as MBACK, I would get a better results. So I decided to use it for the normalization and unlike in Athena, the normalized intensity of the spectra does not equal to 1. By saying this, the intensity of my standard models is way higher than the actual samples. Hence, when I use Athena to fit my real spectra, I would not get a good results. I have also tried using the 3rd derivative of my absorption spectra, but the fitting results are even worse. The intensity of the "fit" spectra is way higher than the actual spectra of my samples that I am trying to fit it with. In fact, when I stack the spectra from the standards and the sample together, the 3rd derivative peak of the samples is almost completely flat due to the very high intensity of the standards themselves. What did I do wrong? and what can I do to fix it? I have also attached my samples and standards spectra. Thank you very much for the assistance. Niken

Niken Wijaya writes:
Hi Everyone,
I am facing a lot of problems when I am trying to fit my sample's spectra with my standards one. Initially, I used Athena to do the background subtraction, but the fitting results are just too "funny". The fitting does not really fit the actual spectra. Since I am analyzing Sulphur and many papers has reported how it is prone to self-absorption effect, I thought, probably if I am using a better background subtraction such as MBACK, I would get a better results. So I decided to use it for the normalization and unlike in Athena, the normalized intensity of the spectra does not equal to 1. By saying this, the intensity of my standard models is way higher than the actual samples. Hence, when I use Athena to fit my real spectra, I would not get a good results. I have also tried using the 3rd derivative of my absorption spectra, but the fitting results are even worse. The intensity of the "fit" spectra is way higher than the actual spectra of my samples that I am trying to fit it with. In fact, when I stack the spectra from the standards and the sample together, the 3rd derivative peak of the samples is almost completely flat due to the very high intensity of the standards themselves.
What did I do wrong? and what can I do to fix it? I have also attached my samples and standards spectra.
Thank you very much for the assistance.
Hi Niken, It's a little hard to know what's going on. The reason that we like having Athena project files attached to these postings is because it is then much easier to evaluate the provenance of the problem. That is, the Athena project file retains some of the history of the data. We can evaluate how you have processed the data to arrive at the point of having a problem with the analysis. Given the text files you have attached, it is very difficult to know how to advise you because it is very difficult to understand the problem you are having. I know that you tried to explain the problem, but a picture is, as they say, worth a thousand (unlear, slightly rambly) words. That said, I do have a few comments. 1. There are good reasons to use an algorithm like MBACK rather than the simpler pre- and post-edge normalizaton that Athena offers. Fixing the problem of self-absorption is not one of those reasons. Self-absorption makes the fine structure oscillations smaller. No normalization algorithm will magically undo that problem. Although Athena (or other software) might have a tool for correcting self-absorption, the only really good way of dealing with that problem is to not have it inthe first place. For some samples, self absorption is unavoidable. But if it is possible to modify your sample to minimize that effect, then you should most certainly do so. 2. The third derivative might be a useful tool, as you say. It is, however, esential that you make your Nth derivative spectrum (regardless of the value of N) on normalized data or else the data you examine will not be on the same scale. Another issue with high order derivatives is that they tend to amplify the size of the noise with respect to the signal. One of your spectra has that problem. Analysis of derivative spectra is one of the few situations in which I think that smoothing is helpful and defensible. If you choose to pursue this issue further here on the mailing list, I encourage you not only to add a project file, but to avoid the sort of fuzzy language you used in this posting. Saying things like "funny fitting results" and "way higher intensities" is just to unclear and subjective. It often helps to attach a screenshot to better demonstrate what you are trying to say. B -- Bruce Ravel ------------ bruceravel1@gmail.com Homepage --------------- http://xafs.org/BruceRavel EXAFS software --------- http://github.com/bruceravel/demeter/
On 3/09/2011 10:43 PM, bruceravel1@gmail.com wrote:
Niken Wijaya writes:
Hi Everyone,
I am facing a lot of problems when I am trying to fit my sample's spectra with my standards one. Initially, I used Athena to do the background subtraction, but the fitting results are just too "funny". The fitting does not really fit the actual spectra. Since I am analyzing Sulphur and many papers has reported how it is prone to self-absorption effect, I thought, probably if I am using a better background subtraction such as MBACK, I would get a better results. So I decided to use it for the normalization and unlike in Athena, the normalized intensity of the spectra does not equal to 1. By saying this, the intensity of my standard models is way higher than the actual samples. Hence, when I use Athena to fit my real spectra, I would not get a good results. I have also tried using the 3rd derivative of my absorption spectra, but the fitting results are even worse. The intensity of the "fit" spectra is way higher than the actual spectra of my samples that I am trying to fit it with. In fact, when I stack the spectra from the standards and the sample together, the 3rd derivative peak of the samples is almost completely flat due to the very high intensity of the standards themselves.
What did I do wrong? and what can I do to fix it? I have also attached my samples and standards spectra.
Thank you very much for the assistance.
Hi Niken,
It's a little hard to know what's going on. The reason that we like having Athena project files attached to these postings is because it is then much easier to evaluate the provenance of the problem. That is, the Athena project file retains some of the history of the data. We can evaluate how you have processed the data to arrive at the point of having a problem with the analysis.
Given the text files you have attached, it is very difficult to know how to advise you because it is very difficult to understand the problem you are having. I know that you tried to explain the problem, but a picture is, as they say, worth a thousand (unlear, slightly rambly) words.
That said, I do have a few comments.
1. There are good reasons to use an algorithm like MBACK rather than the simpler pre- and post-edge normalizaton that Athena offers. Fixing the problem of self-absorption is not one of those reasons. Self-absorption makes the fine structure oscillations smaller. No normalization algorithm will magically undo that problem.
Although Athena (or other software) might have a tool for correcting self-absorption, the only really good way of dealing with that problem is to not have it inthe first place. For some samples, self absorption is unavoidable. But if it is possible to modify your sample to minimize that effect, then you should most certainly do so.
2. The third derivative might be a useful tool, as you say. It is, however, esential that you make your Nth derivative spectrum (regardless of the value of N) on normalized data or else the data you examine will not be on the same scale. Another issue with high order derivatives is that they tend to amplify the size of the noise with respect to the signal. One of your spectra has that problem. Analysis of derivative spectra is one of the few situations in which I think that smoothing is helpful and defensible.
If you choose to pursue this issue further here on the mailing list, I encourage you not only to add a project file, but to avoid the sort of fuzzy language you used in this posting. Saying things like "funny fitting results" and "way higher intensities" is just to unclear and subjective. It often helps to attach a screenshot to better demonstrate what you are trying to say.
B
Hi Bruce, Thank you for the comments. Attached is the project files and the figure. Here are the problems and comments I am having right now. 1. As you can see on the figure (i.e. filename: ifeffitlist-sample1 fitting), the intensity of the fitting spectra is higher than the actual sample. This is I believe due to the higher intensity of the individual standard compounds when compared to the spectra of my samples (i.e. filename: ifeffitlist-intensity). This is the case for every fitting I did for my sample so I am just not sure with the fitting results. 2. If we see figure "ifeffitlist-sample39", we can see that the spectra has different slopes on the pre and post-edge region. When I used MBACK for background removal, the normalized spectra is weird, illustrated in "sample39-fig-norm.pdf". What is the best way to fix this issue? I have 5 samples with this feature that I cannot process due to the weird normalized spectra. 3. Regarding the self-absorption correction, I was not aware that Athena has this function. I will have a look at the manual again. Thank you for letting me know. 4. With the 3rd derivative spectrum, I did indeed derive it from the normalized values. As you can see from the file I attached earlier, from the experts points of view, do you think I should go on with the Nth derivative spectra or due to the very low signal-to-noise ratio of the spectra, I should just focus on the absorption spectra? Again, thank you for the invaluable inputs. Regards, Niken

On Sunday, September 04, 2011 08:52:30 pm Niken Wijaya wrote:
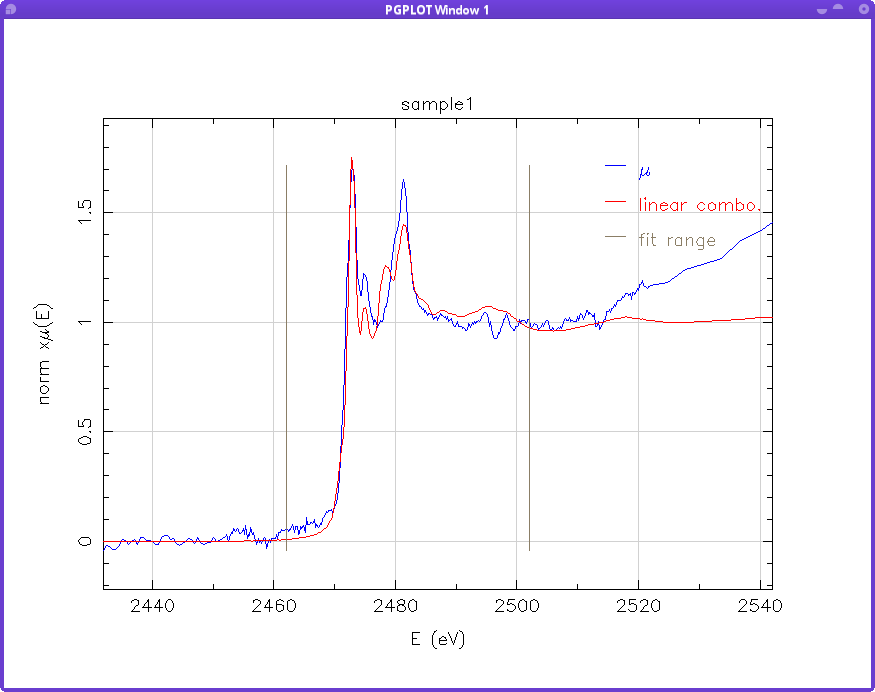
1. As you can see on the figure (i.e. filename: ifeffitlist-sample1 fitting), the intensity of the fitting spectra is higher than the actual sample. This is I believe due to the higher intensity of the individual standard compounds when compared to the spectra of my samples (i.e. filename: ifeffitlist-intensity). This is the case for every fitting I did for my sample so I am just not sure with the fitting results.
Well, there are a lot of problems contributing to your confusion. One thing that probably doesn't help, but which certainly isn't the central problem, is that you have extremely large values for the y-axis offset parameter of several of the standards. This makes it difficult to plot normalized spectra in an unconfusing way. Your central problem is that, for most of the data groups, the values of parameters for the pre-edge and normalization lines are not well chosen. It would seem that you trusted the default values without checking them. See http://cars9.uchicago.edu/~ravel/software/doc/Athena/html/bkg/norm.html In your case, the default values resulted in unusably short ranges for thepre-edge line or the post-edge line or both. The moral of this story is to plot the data with its pre- and post-edge lines to verify that the values result in sensible normalization. See http://cars9.uchicago.edu/~ravel/software/doc/Athena/html/plot/tabs.html You also had a problem that some of your data were somehow imported as normalized mu(E) rather than as mu(E) or xanes(E). See http://cars9.uchicago.edu/~ravel/software/doc/Athena/html/import/columns.htm... This is usually not a good idea as it tells Athena that your data are already reliably normalized and should not be further processed. Those data, however, were not unit edge-step normalized, which is what the LCF utility requires. The way to fix that in an existing Athena project file is explained just a little further down on that same page. Once I fixed the datatype for all of your groups and performed a sensible normalization for your data, I got the LCF fit shown in the attached image. Not great, but not the ridiculous result you were getting with so many things done wrongly in your project file. I think that the underlying problem is that you expected Athena to magically do the right thing with your data without verifying its results. Or, perhaps, you plowed forward without fully understanding how to use the program. The documentation isn't exactly exciting reading, but it doesn't completely suck. You might want to bookmark its URL.
2. If we see figure "ifeffitlist-sample39", we can see that the spectra has different slopes on the pre and post-edge region. When I used MBACK for background removal, the normalized spectra is weird, illustrated in "sample39-fig-norm.pdf". What is the best way to fix this issue? I have 5 samples with this feature that I cannot process due to the weird normalized spectra.
Well, MBACk isn't my thing, so I can only comment on it in general terms. I suspect that you would get better results if you severely truncated your data, say from about 2455 to 2515. Something wonky happens in that spectrum at the beginning and the end. I suspect that MBACK is having trouble figuring out what part of the data is actually the edge step.
3. Regarding the self-absorption correction, I was not aware that Athena has this function. I will have a look at the manual again. Thank you for letting me know.
http://cars9.uchicago.edu/~ravel/software/doc/Athena/html/process/sa.html Again, not exciting ... doesn't suck ... bookmark. Here's a talk I gave at the University of Ghent last January on the topic of self-absortion corrections. It may be of some help to you: http://cars9.uchicago.edu/~ravel/misc/selfabs.pdf
4. With the 3rd derivative spectrum, I did indeed derive it from the normalized values. As you can see from the file I attached earlier, from the experts points of view, do you think I should go on with the Nth derivative spectra or due to the very low signal-to-noise ratio of the spectra, I should just focus on the absorption spectra?
I don't really have an opinion one way or the other about the 3rd derivative. The folks from Stanford and CLS who do a lot of sulfur work have made extensive use of the 3rd derivative and they are really smart people. I haven't done a lot of S work in my own career and none of Athena's users have ever asked for a 3rd derivative option, so Athena doesn't currently do that. B PS: Doesn't it just blow your mind how there is a strong correlation between quality and clarity of the question and specificity of the answer? Amazing...! -- Bruce Ravel ------------------------------------ bravel@bnl.gov National Institute of Standards and Technology Synchrotron Methods Group at NSLS --- Beamlines U7A, X24A, X23A2 Building 535A Upton NY, 11973 My homepage: http://xafs.org/BruceRavel EXAFS software: http://cars9.uchicago.edu/ifeffit/Demeter
{kind=link}
On 7/09/2011 7:24 AM, Bruce Ravel wrote:
On Sunday, September 04, 2011 08:52:30 pm Niken Wijaya wrote:
1. As you can see on the figure (i.e. filename: ifeffitlist-sample1 fitting), the intensity of the fitting spectra is higher than the actual sample. This is I believe due to the higher intensity of the individual standard compounds when compared to the spectra of my samples (i.e. filename: ifeffitlist-intensity). This is the case for every fitting I did for my sample so I am just not sure with the fitting results. Well, there are a lot of problems contributing to your confusion.
One thing that probably doesn't help, but which certainly isn't the central problem, is that you have extremely large values for the y-axis offset parameter of several of the standards. This makes it difficult to plot normalized spectra in an unconfusing way.
Your central problem is that, for most of the data groups, the values of parameters for the pre-edge and normalization lines are not well chosen. It would seem that you trusted the default values without checking them. See
http://cars9.uchicago.edu/~ravel/software/doc/Athena/html/bkg/norm.html
In your case, the default values resulted in unusably short ranges for thepre-edge line or the post-edge line or both. The moral of this story is to plot the data with its pre- and post-edge lines to verify that the values result in sensible normalization. See
http://cars9.uchicago.edu/~ravel/software/doc/Athena/html/plot/tabs.html
You also had a problem that some of your data were somehow imported as normalized mu(E) rather than as mu(E) or xanes(E). See
http://cars9.uchicago.edu/~ravel/software/doc/Athena/html/import/columns.htm...
This is usually not a good idea as it tells Athena that your data are already reliably normalized and should not be further processed. Those data, however, were not unit edge-step normalized, which is what the LCF utility requires. The way to fix that in an existing Athena project file is explained just a little further down on that same page.
Once I fixed the datatype for all of your groups and performed a sensible normalization for your data, I got the LCF fit shown in the attached image. Not great, but not the ridiculous result you were getting with so many things done wrongly in your project file.
I think that the underlying problem is that you expected Athena to magically do the right thing with your data without verifying its results. Or, perhaps, you plowed forward without fully understanding how to use the program. The documentation isn't exactly exciting reading, but it doesn't completely suck. You might want to bookmark its URL.
2. If we see figure "ifeffitlist-sample39", we can see that the spectra has different slopes on the pre and post-edge region. When I used MBACK for background removal, the normalized spectra is weird, illustrated in "sample39-fig-norm.pdf". What is the best way to fix this issue? I have 5 samples with this feature that I cannot process due to the weird normalized spectra. Well, MBACk isn't my thing, so I can only comment on it in general terms. I suspect that you would get better results if you severely truncated your data, say from about 2455 to 2515. Something wonky happens in that spectrum at the beginning and the end. I suspect that MBACK is having trouble figuring out what part of the data is actually the edge step.
3. Regarding the self-absorption correction, I was not aware that Athena has this function. I will have a look at the manual again. Thank you for letting me know. http://cars9.uchicago.edu/~ravel/software/doc/Athena/html/process/sa.html
Again, not exciting ... doesn't suck ... bookmark.
Here's a talk I gave at the University of Ghent last January on the topic of self-absortion corrections. It may be of some help to you:
http://cars9.uchicago.edu/~ravel/misc/selfabs.pdf
4. With the 3rd derivative spectrum, I did indeed derive it from the normalized values. As you can see from the file I attached earlier, from the experts points of view, do you think I should go on with the Nth derivative spectra or due to the very low signal-to-noise ratio of the spectra, I should just focus on the absorption spectra? I don't really have an opinion one way or the other about the 3rd derivative. The folks from Stanford and CLS who do a lot of sulfur work have made extensive use of the 3rd derivative and they are really smart people. I haven't done a lot of S work in my own career and none of Athena's users have ever asked for a 3rd derivative option, so Athena doesn't currently do that.
B
PS: Doesn't it just blow your mind how there is a strong correlation between quality and clarity of the question and specificity of the answer? Amazing...!
_______________________________________________ Ifeffit mailing list Ifeffit@millenia.cars.aps.anl.gov http://millenia.cars.aps.anl.gov/mailman/listinfo/ifeffit Hi Bruce,
I think I have to clarify that I used MBACK to do the normalization instead of ATHENA. This might as well explain why I got such a high value of y-axis offset, why you think I did not choose the right parameters for the "pre-edge" and "normalization range" and also why I imported the data as normalized mu(E) rather than mu(E). As mentioned in the manual, doing normalization in Athena is very subjective, tiny difference in the point chosen for both the "pre-edge region" and "normalization range" will result in different normalized spectra. Due to lack of experience in processing XAFS spectra and noisy spectra obtained, I was planning to eliminate this problem by using MBACK. My initial plan was to combine the benefit I can get from both ATHENA and MBACK. So, I did the normalization using MBACK, then do the self-absorption correction and fit the normalized spectra in ATHENA. However, looking at your comment, LCF in ATHENA requires edge-step normalization, by saying that, does it mean that I cannot normalized my spectra using MBACK then fit them in ATHENA? Thanks, Niken
On Wednesday, September 07, 2011 07:52:38 pm Niken Wijaya wrote:
I think I have to clarify that I used MBACK to do the normalization instead of ATHENA. This might as well explain why I got such a high value of y-axis offset, why you think I did not choose the right parameters for the "pre-edge" and "normalization range" and also why I imported the data as normalized mu(E) rather than mu(E). As mentioned in the manual, doing normalization in Athena is very subjective, tiny difference in the point chosen for both the "pre-edge region" and "normalization range" will result in different normalized spectra. Due to lack of experience in processing XAFS spectra and noisy spectra obtained, I was planning to eliminate this problem by using MBACK. My initial plan was to combine the benefit I can get from both ATHENA and MBACK. So, I did the normalization using MBACK, then do the self-absorption correction and fit the normalized spectra in ATHENA. However, looking at your comment, LCF in ATHENA requires edge-step normalization, by saying that, does it mean that I cannot normalized my spectra using MBACK then fit them in ATHENA?
Niken, So, you want to use MBACK because it is less subjective than Autobk. How, then, do you then plan to do your self absorption correction in a similarly and defensibly rigorous manner? I am suspicious that you have not thought this through very well. Your original email suggested that you believed there to be a problem with Athena. A cursory examination of your work -- once you actually did the favor of posting a project file -- made it clear to me that you are not using the program correctly. Indeed, in one of your emails, you made it clear that you have never read the documentation. I am unaware of a bug in Athena that precludes using data normalized outside of Athena to do LCF within Athena. That may not be the mornal mode of operation, but it is a reasonable thing to want to do. You must take care to import the data correctly and verify that the form of your data has been preserved before performing the LCF. If you expect the program to magically do what you want rather then observing how the program actually behaves, it is unlikely that you will be satisfied with the results. Is it possible that there is a bug that precludes Athena from doing this thing? Of course. A quick examination of the archives of this mailing list should make it clear that my software is *way* less than perfect. So far, you have not given me any reason to belive that's the case. B -- Bruce Ravel ------------------------------------ bravel@bnl.gov National Institute of Standards and Technology Synchrotron Methods Group at NSLS --- Beamlines U7A, X24A, X23A2 Building 535A Upton NY, 11973 My homepage: http://xafs.org/BruceRavel EXAFS software: http://cars9.uchicago.edu/ifeffit/Demeter

Niken, Have you compared MBACK to using the 'CLnorm' normalization in Athena (found under "Background Removal Additional Parameters")? The algorithms are not identical, but have a lot in common, and would probably make it easier to compare with other data in Athena. If I understand correctly, your sulfur spectra were not collected in fluorescence with a solid-state detector, so that part of what MBACK is really good at doesn't apply, and the CLnorm normalization is pretty close to other part of MBACK. I'd be interested to know if you or anyone else has done a careful study comparing MBACK, CLnorm, and other normalization procedures. --Matt
participants (4)
-
 Bruce Ravel
Bruce Ravel -
 bruceravel1@gmail.com
bruceravel1@gmail.com -
 Matt Newville
Matt Newville -
 Niken Wijaya
Niken Wijaya