Re: [Ifeffit] Distortion of transmission spectra due to particle size

Let me try again. First of all, perhaps you missed that after my first post, I acknowledged that my statement in the first post was mistaken? In fact, I later said:
So there's nothing wrong with the arguments in Lu and Stern, Scarrow, etc.--it's the notion I had that we use multiple layers of tape to improve uniformity that's mistaken.
The Lu and Stern paper, which I now agree with, comes up with an equation I have attached as a png file. That equation is derived for spheres of diameter D in a monolayer. It does, incidentally, include a typo; the part inside the ln should start with mu_2^2/mu_1^2. But that's just typographical, and doesn't affect their subsequent argument. Lu and Stern then make the following claim:
Finally, the attenuation in N layers is given by (I/I0)^N, where I is the transmitted intensity through one layer. Chi_eff for N layers is then the same as for a single layer since N will cancel in the final result.
That's the statement I initially thought was incorrect, and thought was equivalent to a non-random stacking of layers. Since I'm now convinced that the statement is correct, I don't want to get bogged down in a discussion of why I still find it a bit puzzling. Other than my first post, no one else in this thread has yet challenged the Lu and Stern statement, and some, such as Matthew Marcus, have supported it. The statement can be rephrased to say that, for a given particle diameter D, the ratio of chi_eff to chi_real is independent of the number of layers; that is, the distortion due to nonuniformity is not reduced by adding additional identical layers. I found this conclusion so startling that at first I rejected it. Several others in this thread indicated that they too tended to think that additional identical layers would reduce distortions in the spectrum due to nonuniformity. I then tested this principle that emerges from the Lu and Stern paper in two other situations, and found that it holds in those as well. Here are the details: The first case I'll examine is a Gaussian distribution of standard deviation sigma and average width x_o, with a distribution narrow enough so that we can ignore the negative-thickness tail. Grant Bunker has investigated this case, for example on page 88 of his new textbook. The derivation is straightforward, and he finds that (mu x)_eff = mu x_o - (mu sigma)^2/2 Your simulation beautifully demonstrates that when I use N layers of this type, we can expect that the new mean thickness x_new = N x_o, and sigma_new = sqrt(N) sigma. This gives: (mu x)_new_eff = mu N x_o - [mu sqrt(N) sigma]^2/2 = N [mu x_o - (mu sigma)^2/2] = N (mu x)_eff Thus the new spectrum is exactly the same shape as the old spectrum-- just scaled up by a factor of N. Therefore, after normalization, the spectrum of the multi-layer sample will be exactly the same as for the single layer. (Note that this analysis does not include the effect of signal to noise, harmonics, etc.). Thus the distortion due to nonuniformity is independent of the number of identical layers used. My next thought was to see if this was a peculiarity of normally distributed samples and monolayers of spheres. After all, extremely nonuniform samples will tend to approach a Gaussian thickness distribution as more layers are randomly stacked up--perhaps they asymptotically approach the distortion present in the Gaussian case? So I investigated pinholes. This time I did the calculation all the way from scratch, just to make sure I understood all the assumptions. Take a sample that has a fraction p of pinholes, with the remaining 1- p of the sample being of uniform thickness x. In that case, I = p I_o + (1-p) I_o exp(-mu x) mu_eff = ln (I/I_o) = ln [p + (1-p) exp(-mu x)] Now take two layers of that type, with the pinholes randomly distributed. A fraction p^2 will still be pinhole, a fraction 2p(1-p) will have thickness x, and a fraction (1-p)^2 will have thickness x^2. So now I/I_o = p^2 + 2p(1-p) exp(-mu x) + (1-p)^2 exp(-2 mu x) mu_eff = ln[p^2 + 2p(1-p) exp(-mu x) + (1-p)^2 exp(-2 mu x)] = ln[p+(1- p)exp(-mu x)]^2 = 2ln[p + (1-p) exp(-mu x)] And that is exactly twice the mu_eff of the single layer--i.e., after normalization it will be identical. Any distortions caused by pinholes will be identical, despite the fraction of sample having pinholes all the way through dropping from p to p^2. Some in our community already realized that, but I didn't. In fact, I'd go so far as to say I was shocked by the result. Judging by some of the advice that is routinely given about sample preparation, I suspect that this may come as a surprise to many others as well. Hopefully that establishes what my understanding currently is. Beyond that, we seem to be miscommunicating on some questions of terminology: On Nov 24, 2010, at 12:04 PM, Matt Newville wrote:
Scott,
You said:
the distortion from nonuniformity is as bad for four strips stacked as for the single strip.
As I showed earlier, a four layer sample is more uniform than a one layer sample, whether the total thickness is preserved or the thickness per layer is preserved.
For 1% pinholes: # N_layers | % Pinholes | Ave Thickness | Thickness Std Dev | # 1 | 1.0 | 0.990 | 0.099 | # 5 | 1.0 | 4.950 | 0.225 | # 25 | 1.0 | 24.750 | 0.500 |
Yes, the sample with 25 layers has a more uniform thickness.
As before, the standard deviation increases as square root of N. Using a cumulant expansion (admittedly slightly funky for such a broad distribution) necessarily yields the same result as the Gaussian distribution: the shape of the measured spectrum is independent of the number of layers used! And as it turns out, an exact calculation (i.e. not using a cumulant expansion) also yields the same result of independence.
OK... The shape is the same, but the relative widths change.
24.75 +/- 0.50 is a more uniform distribution than 0.99 +/- .099. Perhaps this is what is confusing you?
The thicker sample is more uniform (in the sense of fractional uniformity), but the distortion in the normalized mu(E) due to the nonuniformity is identical. That is exactly what is surprising, and what I initially did not believe. Now I am firmly convinced that it is true.
So Lu and Stern got it right. But the idea that we can mitigate pinholes by adding more layers is wrong.
Adding more layers does make a sample of more uniform thickness. Perhaps "mitigate pinholes" means something different to you?
By "mitigate pinholes" I mean that we can obtain a normalized energy spectrum that is closer to the mu(E) we are trying to measure. But we can't do that by adding more identically distributed layers if the thick and thin spots are randomly stacked--we end up with exactly the same normalized mu(E). (As usual, this analysis neglects signal to noise, harmonics, and the like.) I used a lot of words there to try to be precise. But basically, stacking two layers of tape with the hope that pinholes will tend to be cancelled out will not work.
In your original message (in which you set out to "track down" a piece of "incorrect lore") you said that Lu and Stern assumed that layers were stacked "so that thick spots are always over thick and thin spots over thin". They did not assume that. Given that initial misunderstanding, and the fact that you haven't shown any calculations or simulations, it's a bit hard for me to fathom what you think Lu and Stern "got right" or wrong.
They got everything right. I was trying to save a different piece of lore that I think is even more widely disseminated--that stacking thin layers of tape reduces the amount of distortion due to nonuniformity as compared to one thin layer of tape. I thought I had shown calculations (the Gaussian case), and Jeremy has shown simulations which confirm the result for the pinhole case.
The main point of their work is that it is better to use more layers to get to a given thickness. You seem to have some objection to this, but I cannot figure out what you're trying to say.
I agree that your statement is a true one which is also consistent with their paper, but would respectfully differ as to what the main point of the paper is. The abstract reads:
Powdered samples samples are commonly used to measure the extended X- ray absorption fine structure (EXAFS) and near-edge structure. It is shown that sizes of particles typically employed produce significant reduction in the EXAFS amplitude for concentrated samples. The distortion is calculated and found to be in good agreement with measurements on FeSi2 samples. To obtain accurate EXAFS amplitudes on powdered samples it is necessary to use particles significantly smaller than 400 mesh when the atom of interest is concentrated.
The use of increasing number of layers as the particles are sieved more finely is done to provide a controlled experiment in which differences in signal to noise and thickness effects are not a factor. Suggesting that it is better to use more layers to get a given thickness is an indirect way of getting at the real issue, which is particle size. For a given particle size, multiple layers provide no help whatsoever with nonuniformity-related distortions, but merely allow for the desired signal to noise. Lu and Stern provide the correct emphasis in their paper. It is only some of the subsequent XAFS practitioners, including myself until about 24 hours ago, who placed the stress on the multiple layers per se as addressing the uniformity issue. --Scott Calvin Faculty at Sarah Lawrence College Currently on sabbatical at Stanford Synchrotron Radiation Laboratory
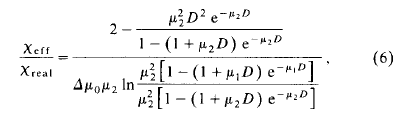{kind=link}

Scott,
Let me try again.
I think I understand you now, and I think I agree completely.
First of all, perhaps you missed that after my first post, I acknowledged that my statement in the first post was mistaken? In fact, I later said:
So there's nothing wrong with the arguments in Lu and Stern, Scarrow, etc.--it's the notion I had that we use multiple layers of tape to improve uniformity that's mistaken.
The Lu and Stern paper, which I now agree with, comes up with an equation I have attached as a png file.
That equation is derived for spheres of diameter D in a monolayer.
I think it's not that important, but Equations 1 through 6 in Lu and Stern discuss the absorption by a single spherical particle, not a monolayer of particles. Absorption by a monolayer would need to include finite packing fraction (pinholes), which this section does not discuss. It only discusses the effect of the varying thickness of a sphere. Incomplete coverage of a layer is in section 4. I am not entirely sure I understand their section 4, and the notation a bit confusing ("f" is not given in Section 2 -- I assume f=Xeff/Xreal, though I am not sure).
Lu and Stern then make the following claim:
Finally, the attenuation in N layers is given by (I/I0)^N, where I is the transmitted intensity through one layer. Chi_eff for N layers is then the same as for a single layer since N will cancel in the final result.
That's the statement I initially thought was incorrect, and thought was equivalent to a non-random stacking of layers. Since I'm now convinced that the statement is correct, I don't want to get bogged down in a discussion of why I still find it a bit puzzling.
Other than my first post, no one else in this thread has yet challenged the Lu and Stern statement, and some, such as Matthew Marcus, have supported it.
The statement can be rephrased to say that, for a given particle diameter D, the ratio of chi_eff to chi_real is independent of the number of layers; that is, the distortion due to nonuniformity is not reduced by adding additional identical layers.
I read their "attenuation of N layers .." to simply being saying that the integrated attenuation over a layer is multiplicative. And, indeed, that multiplication of exponentials is what makes the transmission independent of the number of layers. But as far as I understand, this section is all in the "thin layer" limit. So their statement (and your rephrasing) may be correct only over a limited range of mu and particle size. Again, I think this section is the most confusing part of the manuscript.
I found this conclusion so startling that at first I rejected it. Several others in this thread indicated that they too tended to think that additional identical layers would reduce distortions in the spectrum due to nonuniformity.
I agree. I definitely thought this. I now agree that although the thickness is made more uniform by adding layers, the transmission through that thickness is not decreased, and the measured mu is independent of the number of layers. For a given thickness, a sample of many thin layers not only has a more uniform thickness than a sample with fewer, thicker layers, but also gives less (and so better) transmission.
Take a sample that has a fraction p of pinholes, with the remaining 1-p of the sample being of uniform thickness x. In that case,
I = p I_o + (1-p) I_o exp(-mu x)
mu_eff = ln (I/I_o) = ln [p + (1-p) exp(-mu x)]
Now take two layers of that type, with the pinholes randomly distributed. A fraction p^2 will still be pinhole, a fraction 2p(1-p) will have thickness x, and a fraction (1-p)^2 will have thickness x^2.
So now
I/I_o = p^2 + 2p(1-p) exp(-mu x) + (1-p)^2 exp(-2 mu x)
mu_eff = ln[p^2 + 2p(1-p) exp(-mu x) + (1-p)^2 exp(-2 mu x)] = ln[p+(1-p)exp(-mu x)]^2 = 2ln[p + (1-p) exp(-mu x)]
And that is exactly twice the mu_eff of the single layer--i.e., after normalization it will be identical. Any distortions caused by pinholes will be identical, despite the fraction of sample having pinholes all the way through dropping from p to p^2.
OK, I agree. I think I understand what your point is now. I'm pretty sure you wouldn't disagree, but I just want to reiterate that in the important comparison of 2 layers of thickness t and 1 layer of thickness 2t, there is definitely an important difference. By reducing the thickness of each layer, one reduces the mu dependence of the measured mu. I think you would say is that "many thin layers" versus "few thick layers" is "thickness effect", and should be thought of separately from pinhole effects. I guess I never really had clearly separated those. --Matt PS: If I had calculated mu in my earlier simulations, this would have been more obvious. Attached is a revised simulation code, that does calculate i1_measured and the effective mu. Typical results are: ### total thickness ~= 1, 10% pinholes: ### #nlayers | % holes | t_ave | i1_meas | mu_eff |mu_eff/t_ave| # 1 | 10.0 | 0.900 | 0.4311 | 0.8414 | 0.9349 | # 2 | 10.0 | 0.900 | 0.4171 | 0.8744 | 0.9715 | # 4 | 10.0 | 0.900 | 0.4115 | 0.8879 | 0.9865 | # 10 | 10.0 | 0.900 | 0.4085 | 0.8954 | 0.9949 | ### layer thickness ~= 0.1, 10% pinholes: ### #nlayers | % holes | t_ave | i1_meas | mu_eff |mu_eff/t_ave| # 1 | 10.0 | 0.090 | 0.9144 | 0.0895 | 0.9949 | # 2 | 10.0 | 0.180 | 0.8360 | 0.1791 | 0.9949 | # 4 | 10.0 | 0.360 | 0.6990 | 0.3582 | 0.9949 | # 10 | 10.0 | 0.900 | 0.4085 | 0.8954 | 0.9949 | Here, the ideal mu with no pinholes should be 1. Scott's point is reflected here in the fact that adding layers does not improve mu_eff / t_ave, even though it does improve mu_eff. I think the most important point is that one wants thin layers.
participants (2)
-
 Matt Newville
Matt Newville -
 Scott Calvin
Scott Calvin